什么是合和欠拟合(underfitting and overfitting)?
当训练自己的神经网络时,我们需要高度注意过拟合和欠拟合。欠拟合发生在我们的模型在训练集上不能获得足够低的损失的时候。这种情况下,模型在训练数据上不能学习到潜在的模式。相对的,过拟合发生在网络模型对训练数据模拟的太好且在验证集上泛化的不好的时候。
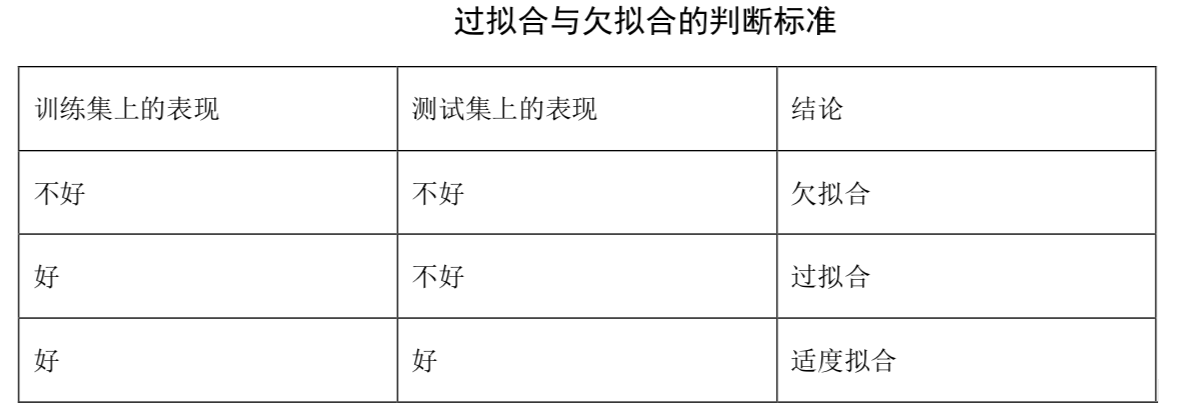
出现过拟合的原因:
训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;
训练集和测试集特征分布不一致;
样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
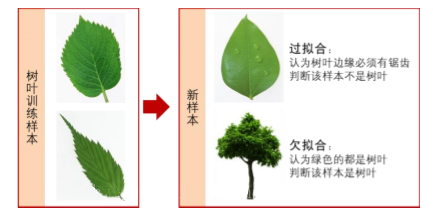
解决方案:
尽可能地降低训练损失;
同时确保训练和测试损失之间的差距相当小。
通过调整神经网络的能力可以控制一个模型是否过拟合或欠拟合。我们通过添加更多的层和神经元来增加能力。类似的,我们可以通过移除层和神经元以及应用正则化技术(权重decay、dropout、数据增加、早停等等)来降低能力。
