搭建基于知识库内容的机器人
如果你仅想要直接实践,可以看最后一部分实践,以及倒数第二部分限制与注意的地方。
简介
这个想法,来源于我的个人需求,我连载了将近 100 期 newsletter,积累了很多内容,我希望将这些资料导入给 AI,然后 AI 能拿这些数据回答我的问题,甚至能给我一些写作建议等。
最早的时候,我尝试过非常笨的方法,就是在提问的时候,将我的 newsletter 文本传给 AI,它的 prompt 大概是这样的:
Please summarize the following sentences to make them easier to understand.Text: """My newsletter"""
这个方法能用是能用,但目前 ChatGPT 有个非常大的限制,它限制了最大的 token 数是 4096,大约是 16000 多个字符,注意这个是请求 + 响应,实际请求总数并没那么多。换句话来说,我一次没法导入太多的内容给 ChatGPT(我的一篇 Newsletter 就有将近 5000 字),这个问题就一直卡了我很久,直到我看到了 GPT Index 的库,以及 Lennys Newsletter 的例子。
试了下,非常好用,而且步骤也很简单,即使你不懂编程也能轻易地按照步骤实现这个功能。
我稍稍优化了下例子的代码,并增加了一些原理介绍。希望大家能喜欢。
原理介绍
其实我这个需求,在传统的机器人领域已经有现成方法,比如你应该看到不少电商客服产品,就有类似的功能,你说一句话,机器人就会回复你。
这种传统的机器人,通常是基于意图去回答人的问题。举个例子,我们构建了一个客服机器人,它的工作原理简单说来是这样的:
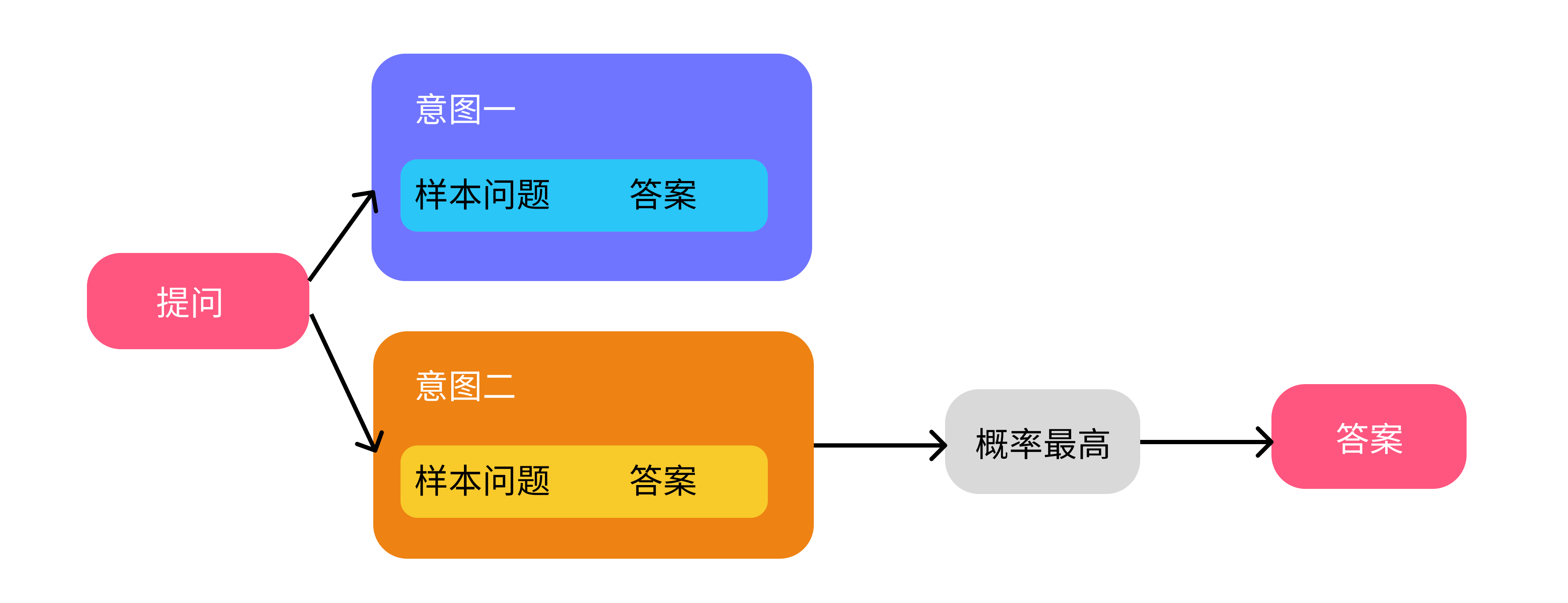
当用户问「忘记密码怎么办?」时,它会去找最接近这个意图「密码」,每个意图里会有很多个样本问题,比如「忘记密码如何找回」「忘记密码怎么办」,然后这些样本问题都会有个答案「点击 A 按钮找回密码」,机器人会匹配最接近样本问题的意图,然后返回答案。
但这样有个问题,我们需要设置特别多的意图,比如「无法登录」、「忘记密码」、「登录错误」,虽然有可能都在描述一个事情,但我们需要设置三个意图、三组问题和答案。
虽然传统的机器人有不少限制,但这种传统方式,给了我们一些灵感。
我们好像可以用这个方法来解决限制 token 的问题,我们仅需要传符合某个意图的文档给 AI,然后 AI 仅用该文档来生成答案:
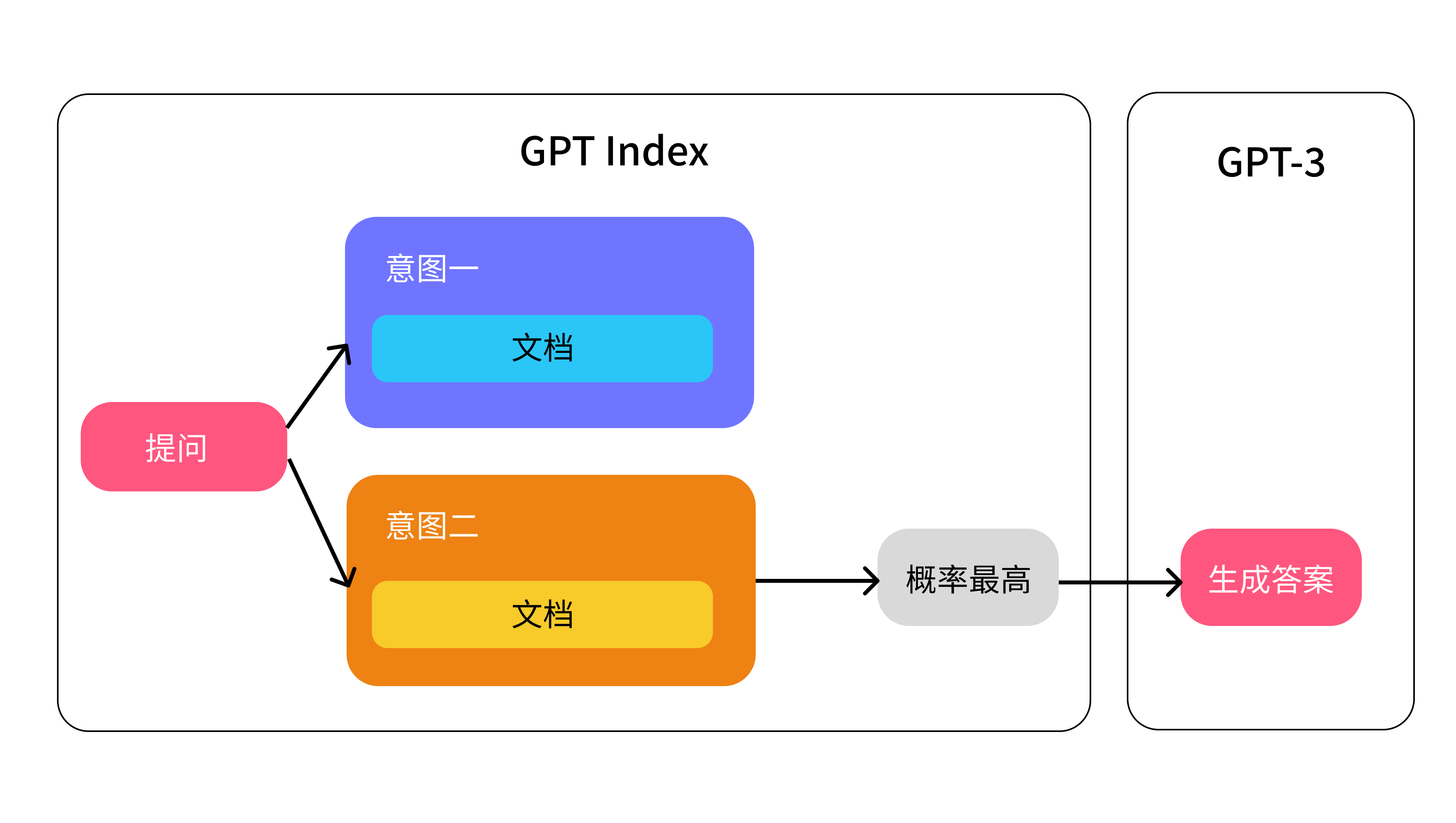
比如还是上面的那个客服机器人的例子,当用户提问「忘记密码怎么办?」时,匹配到了「登录」相关的意图,接着匹配知识库中相同或相近意图的文档,比如「登录异常处理解决方案文档」,最后我们将这份文档传给 GPT-3,它再拿这个文档内容生成答案。
GPTIndex 这个库简单理解就是做上图左边的那个部分,它的工作原理是这这样的:
- 创建知识库或文档索引
- 找到最相关的索引
- 最后将对应索引的内容给 GPT-3
限制与注意的地方
虽然这个方法解决了 token 限制的问题,但也有不少限制:
- 当用户提一些比较模糊的问题时,匹配有可能错误,导致 GPT-3 拿到了错误的内容,最终生成了非常离谱的答案。
- 当用户提问一些没有多少上下文的信息时,机器人有时会生成虚假信息。
所以如果你想用这个技术做客服机器人,建议你:
- 通过一些引导问题来先明确用户的意图,就是类似传统客服机器人那样,搞几个按钮,先让用户点击(比如无法登录)。
- 如果相似度太低,建议增加兜底的回答「很抱歉,我无法回答你的问题,你需要转为人工客服吗?」
实践
为了让大家更方便使用,我将代码放在了 Google Colab,你无需安装任何环境,只需要用浏览器打开这个: 代码文件
BTW 你可以将其复制保存到自己的 Google Drive。
:::info 收到不少朋友的反馈,说下面的按钮没法点击。下面只是截图,你需要打开这个代码文件进行操作。 另外,关于答案不符合预期的问题,主要还是向量匹配的问题,暂时没有解决方案。 :::
第一步:导入数据
导入的方法有两种,第一种是导入在线数据。
导入 GitHub 数据是个相对简单的方式。如果你是第一次使用,我建议你先用这个方法试试。点击下方代码前的播放按钮,就会运行这段代码。

运行完成后,会导入我写的几份 newsletter。如果你也想像我那样导入数据,只需要修改 clone 后面的链接地址即可。
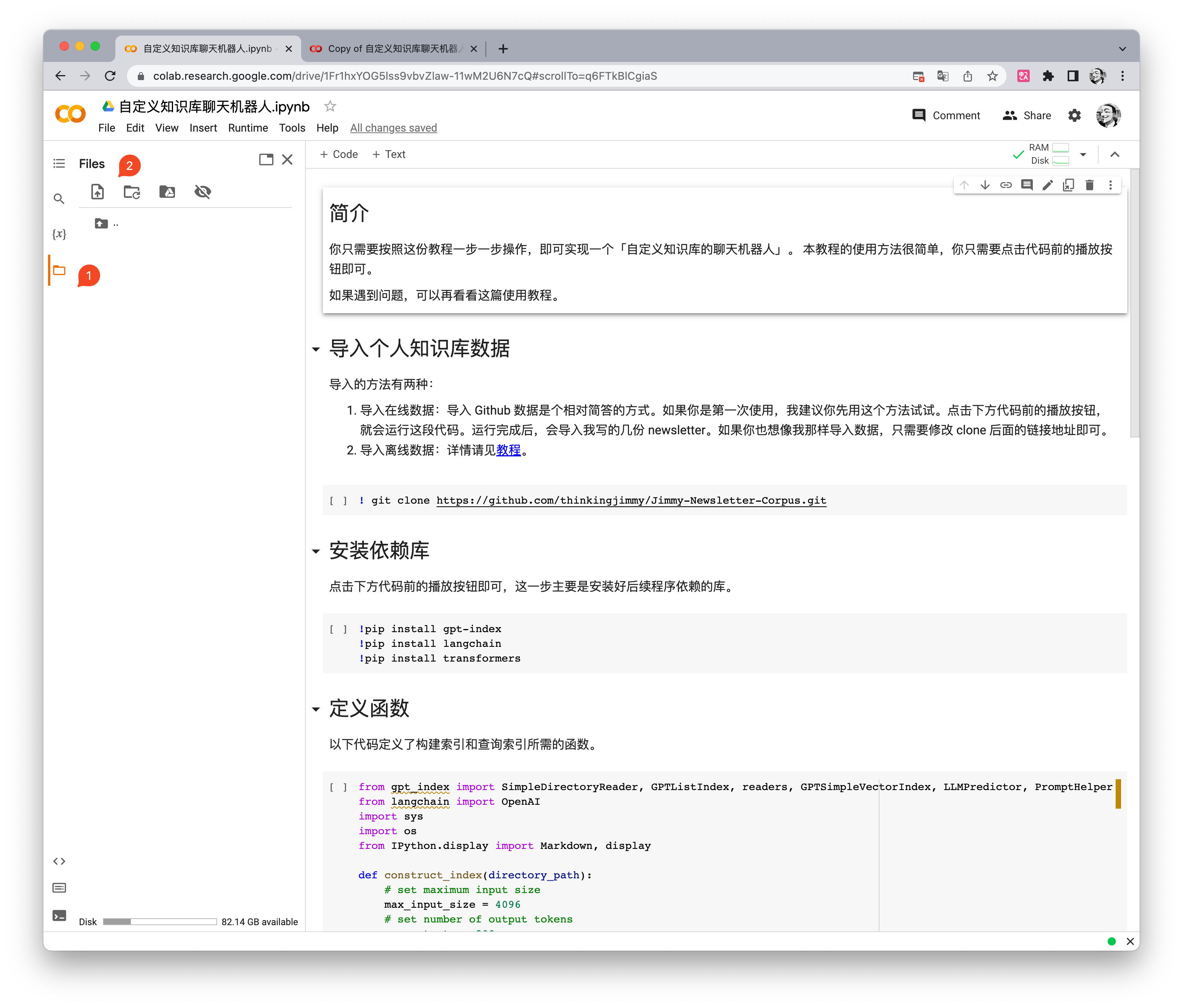
第二种方法是导入离线数据。点击左侧的文件夹按钮(如果你没有登录,这一步会让你登录),然后点击下图标识 2 的上传按钮,上传文件即可。如果你要传多个文件,建议你先建一个文件夹,然后将文件都上传到该文件夹内。
第二 & 三步:安装依赖库
直接点击播放按钮即可。
不过第三步里,你可以尝试改下参数,你可以改:
- num_ouputs :这个是设置最大的输出 token 数,越大,回答问题的时候,机器能回答的字就越多。
- Temperature: 这个主要是控制模型生成结果的随机性。简而言之,温度越低,结果越确定,但也会越平凡或无趣。如果你想要得到一些出人意料的回答,不妨将这个参数调高一些。但如果你的场景是基于事实的场景,比如数据提取、FAQ 场景,此参数就最好调成 0。
其他参数不去管它就好,问题不大。
第四步:设置 OpenAI API Key
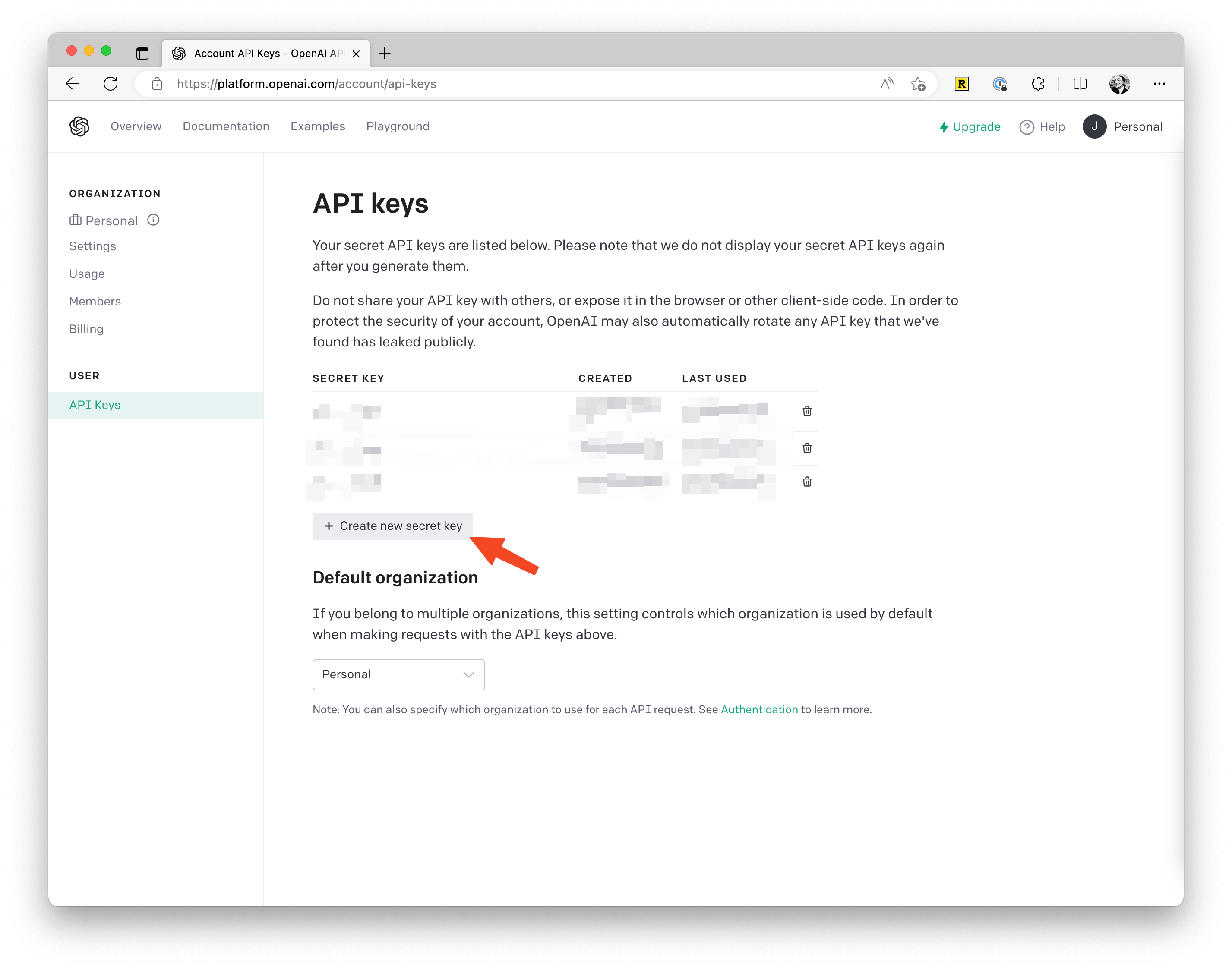
这个需要你登录 OpenAI(注意是 OpenAI 不是 ChatGPT),点击右上角的头像,点击 View API Keys,或者你点击这个链接也可以直接访问。然后点击「Create New Secret Key」,然后复制那个 Key 并粘贴到文档里即可。
第五步:构建索引
这一步程序会将第一步导入的数据都跑一遍,并使用 OpenAI 的 embedings API。如果第一步你上传了自己的数据,只需要将 ‘ ‘ 里的 Jimmy-Newsletter-Corpus 修改为你上传的文件夹名称即可。
注意:
- 这一步会耗费你的 OpenAI 的 Credit,1000 个 token 的价格是 $0.02,运行以下代码前需要注意你的账号里是否还有钱。
- 如果你用的 OpenAI 账号是个免费账号,你有可能会遇到频率警告,此时可以等一等再运行下方代码(另外你的导入的知识库数据太多,也会触发)。解除这个限制,最好的方式是在你的 OpenAI 账号的 Billing 页面里绑定信用卡。如何绑卡,需要各位自行搜索。
第六步:提问
这一步你就可以试试提问了,如果你在第一步导入的是我预设的数据,你可以试试问以下问题:
- Issue 90 主要讲了什么什么内容?
- 推荐一本跟 Issue 90 里提到的书类似的书
如果你导入的是自己的资料,也可以问以下几个类型的问题:
- 总结
- 提问
- 信息提取
