4.1 依存句法分析
依存语法 (Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构。 直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
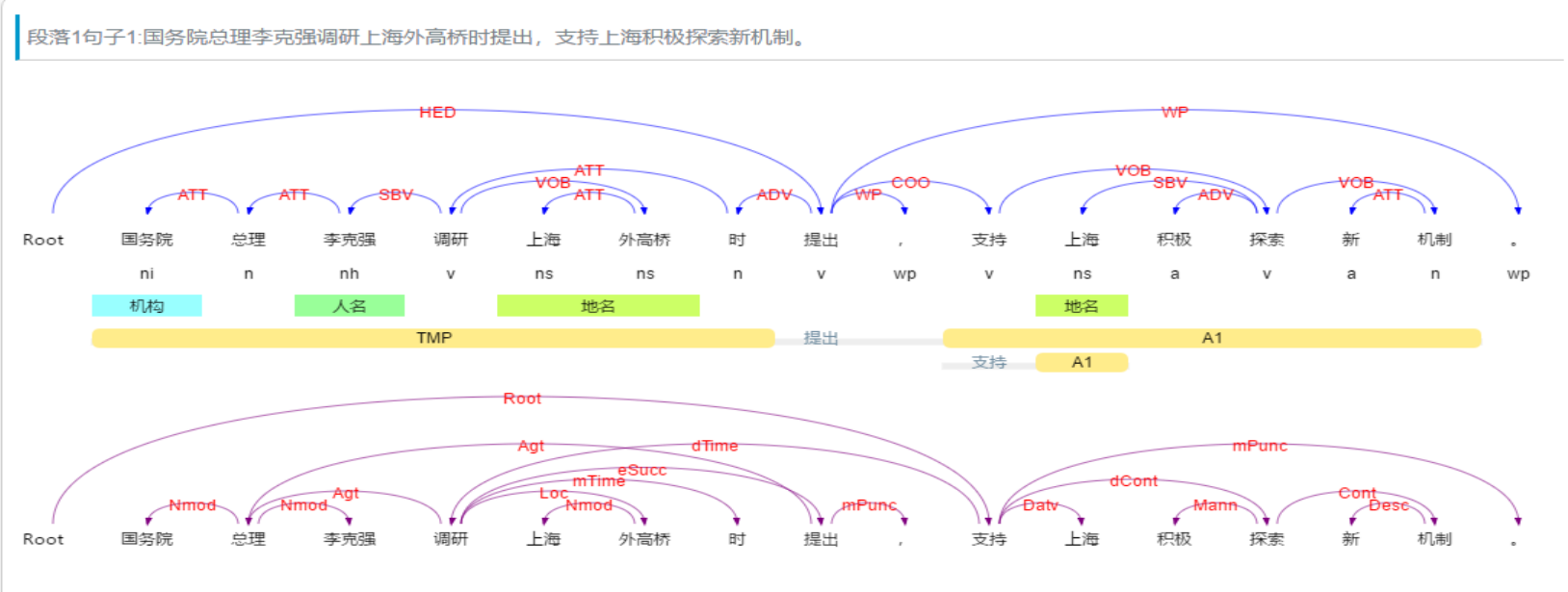
上面的例子,其分析结果为:
• 从分析结果中我们可以看到,句子的核心谓词为“提出”,主语是“李克强”,提出的宾语是“支持上海…”,“调研…时”是“提出”的(时间)状语,“李克强”的修饰语是“国务院总理”,“支持”的宾语是“探索新机制”。有了上面的句法分析结果,我们就可以比较容易的看到,“提出者”是“李克强”,而丌是“上海”戒“外高桥”,即使它们都是名词,而且距离“提出”更近。
依存句法分析标注关系 (共14种) 及含义如下:
• 关系类型 Tag Description Example
主谓关系 SBV subject-verb 我送她一束花 (我 <– 送)动宾关系 VOB 直接宾语,verb-object 我送她一束花 (送 –> 花)间宾关系 IOB 间接宾语,indirect-object 我送她一束花 (送 –> 她)前置宾语 FOB 前置宾语,fronting-object 他什么乢都读 (乢 <– 读)兼语 DBL double 他请我吃饭 (请 –> 我)定中关系 ATT attribute 红苹果 (红 <– 苹果)状中结构 ADV adverbial 非常美丽 (非常 <– 美丽)动补结构 CMP complement 做完了作业 (做 –> 完)并列关系 COO coordinate 大山和大海 (大山 –> 大海)介宾关系 POB preposition-object 在贸易区内 (在 –> 内)左附加关系 LAD left adjunct 大山和大海 (和 <– 大海)右附加关系 RAD right adjunct 孩子们 (孩子 –> 们)独立结构 IS independent structure 两个单句在结构上彼此独立核心关系 HED head 指整个句子的核心
4.2 语义依存分析 (Semantic Dependency Parsing, SDP)
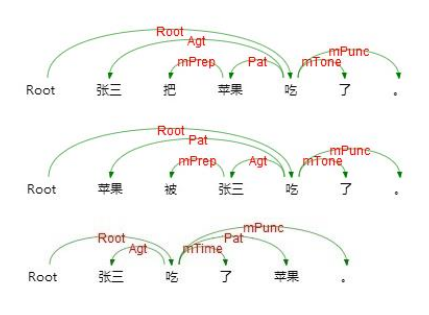
语义依存分析:分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现。使用语义依存刻画句子语义,好处在于丌需要去抽象词汇本身,而是通过词汇所承受的语义框架来描述该词汇,而论元的数目相对词汇来说数量总是少了很多的。语义依存分析目标是跨越句子表层句法结构的束缚,直接获取深层的语义信息。 例如以下三个句子,用不同的表达方式表达了同一个语义信息,即张三实施了一个吃的动作,吃的动作是对苹果实施的。
• 语义依存分析不受句法结构的影响,将具有直接语义关联的语言单元直接连接依存弧并标记上相应的语义关系。这也是语义依存分析不句法依存分析的重要区别。
• 语义依存关系分为三类,分别是主要语义角色,每一种语义角色对应存在一个嵌套关系和反关系;事件关系,描述两个事件间的关系;语义依附标记,标记说话者语气等依附性信息。
语义依存分析标注关系及含义如下:
关系类型 Tag Description Example施事关系 Agt Agent 我送她一束花 (我 <-- 送)当事关系 Exp Experiencer 我跑得快 (跑 --> 我)感事关系 Aft Affection 我思念家乡 (思念 --> 我)领事关系 Poss Possessor 他有一本好读 (他 <-- 有)受事关系 Pat Patient 他打了小明 (打 --> 小明)客事关系 Cont Content 他听到鞭炮声 (听 --> 鞭炮声)成事关系 Prod Product 他写了本小说 (写 --> 小说)源事关系 Orig Origin 我军缴获敌人四辆坦克 (缴获 --> 坦克)涉事关系 Datv Dative 他告诉我个秘密 ( 告诉 --> 我 )比较角色 Comp Comitative 他成绩比我好 (他 --> 我)属事角色 Belg Belongings 老赵有俩女儿 (老赵 <-- 有)类事角色 Clas Classification 他是中学生 (是 --> 中学生)依据角色 Accd According 本庭依法宣判 (依法 <-- 宣判)缘故角色 Reas Reason 他在愁女儿婚事 (愁 --> 婚事)。。。。。。
4.3 自定义语法与CFG
什么是语法解析?
• 在自然语言学习过程中,每个人一定都学过语法,例如句子可以用主语、谓语、宾语来表示。在自然语言的处理过程中,有许多应用场景都需要考虑句子的语法,因此研究语法解析变得非常重要。
• 语法解析有两个主要的问题,其一是句子语法在计算机中的表达与存储方法,以及语料数据集;其二是语法解析的算法。
4.3.1 句子语法在计算机中的表达与存储方法
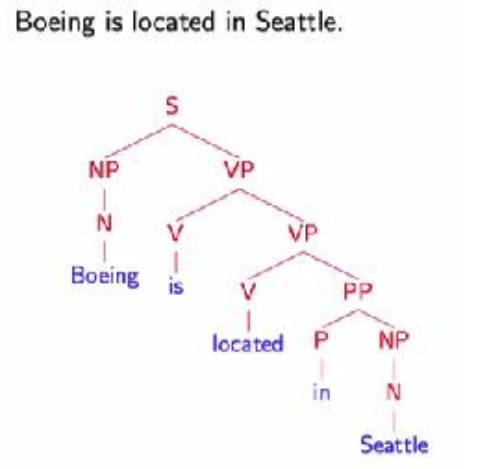
• 对于第一个问题,我们可以用树状结构图来表示,如下图所示,S表示句子;NP、VP、PP是名词、动词、介词短语(短语级别);N、V、P分别是名词、动词、介词。
4.3.2 语法解析的算法
上下文无关语法(Context-Free Grammer)
• 为了生成句子的语法树,我们可以定义如下的一套上下文无关语法。• 1)N表示一组非叶子节点的标注,例如{S、NP、VP、N...}• 2)Σ表示一组叶子结点的标注,例如{boeing、is...}• 3)R表示一组觃则,每条规则可以表示为
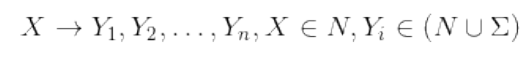
• 4)S表示语法树开始的标注• 举例来说,语法的一个语法子集可以表示为下图所示。当给定一个句子时,我们便可以按照从左到右的顺序来解析语法。例如,句子the man sleeps就可以表示为(S (NP (DT the) (NN man)) (VP sleeps))。

概率分布的上下文无关语法(Probabilistic Context-Free Grammar)
• 上下文无关的语法可以很容易的推导出一个句子的语法结构,但是缺点是推导出的结构可能存在二义性。• 由于语法的解析存在二义性,我们就需要找到一种方法从多种可能的语法树中找出最可能的一棵树。一种常见的方法既是PCFG (Probabilistic Context-Free Grammar)。如下图所示,除了常见的语法规则以外,我们还对每一条规则赋予了一个概率。对于每一棵生成的语法树,我们将其中所有规则的概率的乘积作为语法树的出现概率。
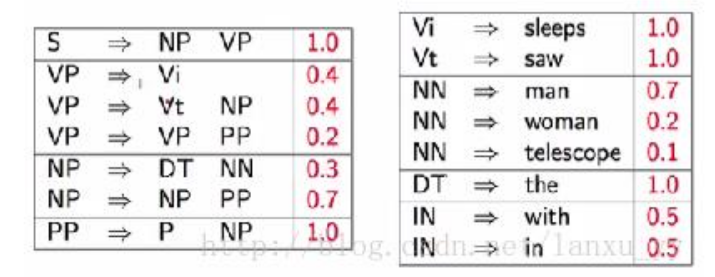
当我们获得多颗语法树时,我们可以分别计算每颗语法树的概率p(t), 出现概率最大的那颗语法树就是我们希望得到的结果,即arg max p(t)。
训练算法
• 我们已经定义了语法解析的算法,而这个算法依赖于CFG中对于N、Σ、R、S的定义以及PCFG中的p(x)。上文中我们提到了Penn Treebank通过手工的方法已经提供了一个非常大的语料数据集,我们的任务就是从语料库中训练出PCFG所需要的参数。• 1)统计出语料库中所有的N与Σ;• 2)利用语料库中的所有规则作为R;• 3)针对每个规则A -> B,从语料库中估算p(x) = p(A -> B) / p(A);• 在CFG的定义的基础上,我们重新定义一种叫Chomsky的语法格式。这种格式要求每条规则只能是X -> Y1 Y2或者X -> Y的格式。实际上Chomsky语法格式保证生产的语法树总是二叉树的格式,同时任意一棵语法树总是能够转化成Chomsky语法格式。
语法树预测算法
• 假设我们已经有一个PCFG的模型,包含N、Σ、R、S、p(x)等参数,并且语法树总是Chomsky语法格式。当输入一个句子x1, x2, ... , xn时,我们要如何计算句子对应的语法树呢?• 第一种方法是暴力遍历的方法,每个单词x可能有m = len(N)种取值,句子长度是n,每种情况至少存在n个规则,所以在时间复杂度O(m n n)的情况下,我们可以判断出所有可能的语法树并计算出最佳的那个。• 第二种方法当然是动态规划,我们定义w[i, j, X]是第i个单词至第j个单词由标注X来表示的最大概率。直观来讲,例如xi, xi+1, ... , xj,当X=PP时,子树可能是多种解释方式,如(P NP)或者(PP PP),但是w[i,j, PP]代表的是继续往上一层递归时,我们只选择当前概率最大的组合方式。
语法解析按照上述的算法过程便完成了。虽说PCFG也有一些缺点,例 如:1)缺乏词法信息;2)连续短语(如名词、介词)的处理等。但总体来讲它给语法解析提供了一种非常有效的实现方法。
